记录一次爬虫心路历程
![]()
前言
朋友的老板给了他一个网站,让他按照分类下载每个分类的所有图,并且按照分类名称作为文件夹命名。近1000多个分类,他跑来跟我抱怨这根本不可能下载完,我安慰他不要着急,然后打开百度。(滑稽)
下面就是制作这个爬虫的经过啦
第一次写爬虫,仅当参考
过程
此处以http://www.jituwang.com为例
图片下载核心
首先我们完成一个爬取某个页面所有图片的方法,这是我们的图片下载核心
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| def getMoviesImg(pagePath):
url = requests.get(pagePath)
html = url.text
soup = BeautifulSoup(html, 'html.parser')
movie = soup.find_all('img')
dir_name = './imgs/' + soup.find('title').text.split(' ')[0]
if not Path(dir_name).is_dir():
os.makedirs(dir_name)
elif not (not os.listdir(dir_name)):
return
x = 1
for i in movie:
imgsrc = i.get('src')
if ("1pixel.gif" in imgsrc) | ("w=32&h=32" in imgsrc) | ("w=16&h=16" in imgsrc):
continue
else:
filename = dir_name + '/%s.jpg' % x
print(filename)
print(imgsrc)
socket.setdefaulttimeout(10)
try:
urllib.request.urlretrieve(imgsrc, filename)
except socket.timeout:
count = 1
while count <= 5:
try:
urllib.request.urlretrieve(imgsrc, filename)
break
except socket.timeout:
err_info = 'Reloading for %d time' % count if count == 1 else 'Reloading for %d times' % count
print(err_info + "\n")
count += 1
if count > 5:
print("download job failed!" + "\n")
print('下载' + str(i) + "\n" + '第' + str(x) + '张' + "\n")
x += 1
print(
'--' + pagePath + ' ------------------------------------------------------------------------------------' + "\n")
print('--下载完成!==========================================================================================' + "\n")
getMoviesImg("https://unsplash.com/t/wallpapers")
|
获取网站数据 → 解析网站 → 解析网站 → 文件判断 → 循环下载
==================================↓
超时重新下载5次 ← 下载图片 ← 过滤不想要的图片 ←
目标页面
其实我们要知道我们去哪里下载图片,也就是目标页面获取
1
2
3
4
5
6
7
8
9
10
11
12
| def getPage(path):
try:
print(path)
time.sleep(5)
soup = BeautifulSoup(requests.get(path).text, 'html.parser')
movie = soup.find('title')
if movie.text.find('404') < 0:
getMoviesImg(path)
except:
traceback.print_exc()
else:
print('ok')
|
我们根据页面索引拼接出目标页面的链接,进行页面预览,404的页面跳过
然后调用getMoviesImg()进行下载
此处有休眠5s防止因频繁请求被拉黑
多线程处理
多个页面目标必须同时爬取,否则会很慢
1
2
3
4
5
6
7
| def getPagePath(datas=None):
if datas is None:
datas = []
datas.sort()
executor = ThreadPoolExecutor(max_workers=10)
all_task = [executor.submit(getPage, index) for index in datas]
wait(all_task, return_when=ALL_COMPLETED)
|
根据传入的分类名称开启10个多线程进行下载
获取分类名称
此时我们仅仅缺少分类列表
1
2
3
4
5
6
7
8
| def getClassList():
url = "https://unsplash.com/t"
soup = BeautifulSoup(requests.get(url).text, 'html.parser')
movie = soup.findAll('a', attrs={"class": "_2tgoq _2WvKc"})
datas = []
for href in movie:
datas.append("https://unsplash.com" + href.get('href'))
getPagePath(datas)
|
获取分类列表,并作为多线程处理方法的参数
至此我们已经可以多线程拔取这个网站所有分类里的图片了
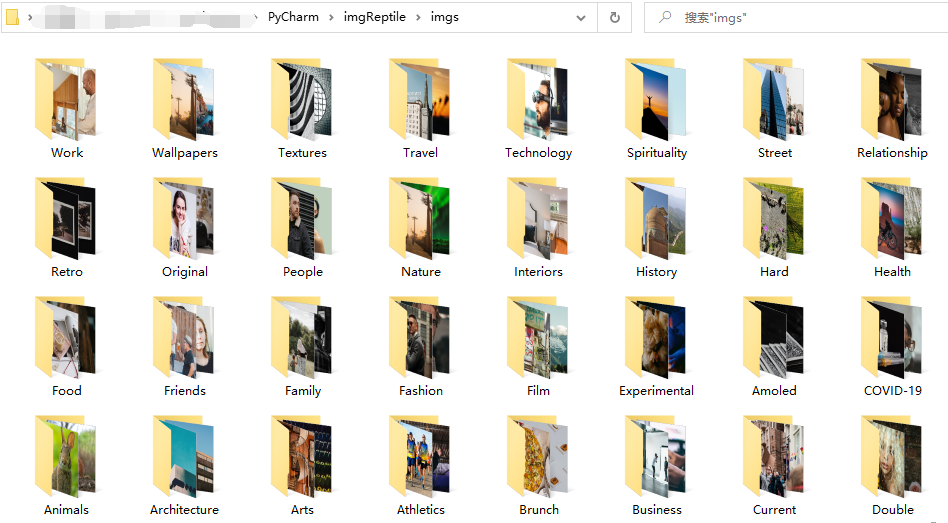
执行结果
![]()
需求完美达成
Code:
如下代码为完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
|
import os
import time
import socket
import requests
import traceback
import urllib.request
from pathlib import Path
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
def getMoviesImg(pagePath):
url = requests.get(pagePath)
html = url.text
soup = BeautifulSoup(html, 'html.parser')
movie = soup.find_all('img')
dir_name = './imgs/' + soup.find('title').text.split(' ')[0]
if not Path(dir_name).is_dir():
os.makedirs(dir_name)
elif not (not os.listdir(dir_name)):
return
x = 1
for i in movie:
imgsrc = i.get('src')
if ("1pixel.gif" in imgsrc) | ("w=32&h=32" in imgsrc) | ("w=16&h=16" in imgsrc):
continue
else:
filename = dir_name + '/%s.jpg' % x
print(filename)
print(imgsrc)
socket.setdefaulttimeout(10)
try:
urllib.request.urlretrieve(imgsrc, filename)
except socket.timeout:
count = 1
while count <= 5:
try:
urllib.request.urlretrieve(imgsrc, filename)
break
except socket.timeout:
err_info = 'Reloading for %d time' % count if count == 1 else 'Reloading for %d times' % count
print(err_info + "\n")
count += 1
if count > 5:
print("download job failed!" + "\n")
print('下载' + str(i) + "\n" + '第' + str(x) + '张' + "\n")
x += 1
print(
'--' + pagePath + ' ------------------------------------------------------------------------------------' + "\n")
print('--下载完成!==========================================================================================' + "\n")
def getPage(path):
try:
print(path)
time.sleep(5)
soup = BeautifulSoup(requests.get(path).text, 'html.parser')
movie = soup.find('title')
if movie.text.find('404') < 0:
getMoviesImg(path)
except:
traceback.print_exc()
else:
print('ok')
def getPagePath(datas=None):
if datas is None:
datas = []
datas.sort()
executor = ThreadPoolExecutor(max_workers=10)
all_task = [executor.submit(getPage, index) for index in datas]
wait(all_task, return_when=ALL_COMPLETED)
def getClassList():
url = "https://unsplash.com/t"
soup = BeautifulSoup(requests.get(url).text, 'html.parser')
movie = soup.findAll('a', attrs={"class": "_2tgoq _2WvKc"})
datas = []
for href in movie:
datas.append("https://unsplash.com" + href.get('href'))
getPagePath(datas)
getClassList()
|
谢谢查阅